统计系统剩余的内存、数据类型转换计算(计算mac地址)、数据类型转换(列表与字典相互转换)...
本文共 1912 字,大约阅读时间需要 6 分钟。
统计系统剩余的内存
1、思路
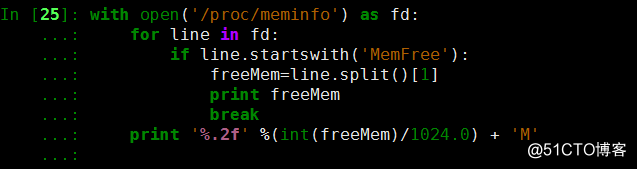
首先对文件遍历;判断当有MemFree这一行开头的,执行下面的语句,line.split()[1]默认以空格为分隔符,取1列的值;最后取2位小数点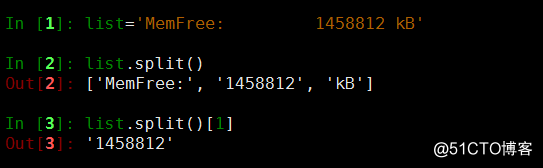
计算:
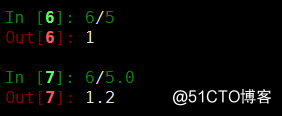
数据类型转换计算(计算mac地址)
需要:有时候我们要把不同的数据类型做一起计算,这时就需要把两个不同的数据类型转换为同种数据类型,否则不同的数据类型不能做计算,比如,字符串之间是不能做加减乘除运算的,必须转化为数值才可以做运算
In [1]: s = 'abc'In [2]: list(s)Out[2]: ['a', 'b', 'c']In [3]: str1='ABCDEF'In [4]: list(str1)Out[4]: ['A', 'B', 'C', 'D', 'E', 'F']
2、字符串转换为元组
In [5]: tuple(str1)Out[5]: ('A', 'B', 'C', 'D', 'E', 'F') 3、元组又转换为字符串
In [7]: tOut[7]: ('A', 'B', 'C', 'D', 'E', 'F')In [8]: ''.join(t)Out[8]: 'ABCDEF' 4、列表转换为字符串
In [12]: lOut[12]: ['A', 'B', 'C', 'D', 'E', 'F']In [13]: ''.join(l)Out[13]: 'ABCDEF'
5、元组转换为列表
In [14]: tOut[14]: ('A', 'B', 'C', 'D', 'E', 'F')In [15]: list(t)Out[15]: ['A', 'B', 'C', 'D', 'E', 'F'] 6、列表转换为元组
In [16]: lOut[16]: ['A', 'B', 'C', 'D', 'E', 'F']In [17]: tuple(l)Out[17]: ('A', 'B', 'C', 'D', 'E', 'F') 7、字典转换为列表
In [18]: dict1={ 'name':'jack','age':'11'}In [19]: dict1.items()Out[19]: [('age', '11'), ('name', 'jack')] 8、列出目录
In [29]: import os Out[29]: ['efi', 'grub2', 'grub', '.vmlinuz-3.10.0-693.el7.x86_64.hmac']9、16进制转化为十进制
In [29]: int('a', 16) Out[29]: 10In [30]: int('ab', 16)
Out[30]: 17110进制转化为16进制
In [37]: hex(123) Out[37]: '0x7b'10、列表转化为字典
In [34]: list1 = [('a', 1), ('b', 2)]In [35]: dict(list1)
Out[35]: {'a': 1, 'b': 2}#比如mac='00:0c:29:ba:27:23',下一位就是'00:0c:29:ba:27:24'
macaddr='00:0c:29:ba:27:ab' prefix_max=macaddr[:-3] #00:0c:29:ba:27 last_two=macaddr[-2:] #23 plus_one=int(last_two,16) + 1 #将16进制转化为10进制 if plus_one in range(10): #如果0~9的数 new_last_two=hex(plus_one)[2:] #将10进制转化为16进制 new_last_two='0'+new_last_two #当plus_one=0~9时,可以前面加上0:,符合mac规范 else: #如果10以上的数,比如hex(12)='0xc' new_last_two=hex(plus_one)[2:] #取[2:],就是c if len(new_last_two) == 1: #len(c)=1,前面加上0;0c,否则就不加 new_last_two='0'+new_last_two new_mac=prefix_max+':'+new_last_two print new_mac.upper() 本文转自 iekegz 51CTO博客,原文链接:http://blog.51cto.com/jacksoner/2056007,如需转载请自行联系原作者
你可能感兴趣的文章
Excel中SEARCH和FIND函数的区别
查看>>
js继承综合
查看>>
[转译]5种方法提高你网站的登录体验
查看>>
关于Grunt
查看>>
linux基础名词
查看>>
(通用)Android App代码混淆终极解决方案【转】
查看>>
《平凡的世界》
查看>>
Mvc Filter
查看>>
数据绑定流程分析
查看>>
hibernate 实现多表连接查询(转载)
查看>>
对一个新知识领域的学习路径
查看>>
ios 获取当前时间
查看>>
算法之求质数(Java语言)
查看>>
Python之旅.第三章.函数
查看>>
WebService学习总结(一)
查看>>
Node.js安装及环境配置之Windows篇
查看>>
初学css为博客园文章某个超链接添加 icon
查看>>
LAMMPS Data Format
查看>>
第一次负责项目总结
查看>>
解决spf13-vim编辑php丢失语法颜色问题
查看>>